 Skip to content
Skip to content 

If you’re working with data, then you know that having a reliable workflow is essential. And if you’re using Amazon Redshift Serverless, then you know that it’s a great platform for managing data.
But what you may not know is that Amazon Redshift now has a Serverless option, which can unlock even more capabilities for your data management.
In this blog post, we’ll explore what Amazon Redshift Serverless can do for you and your data.
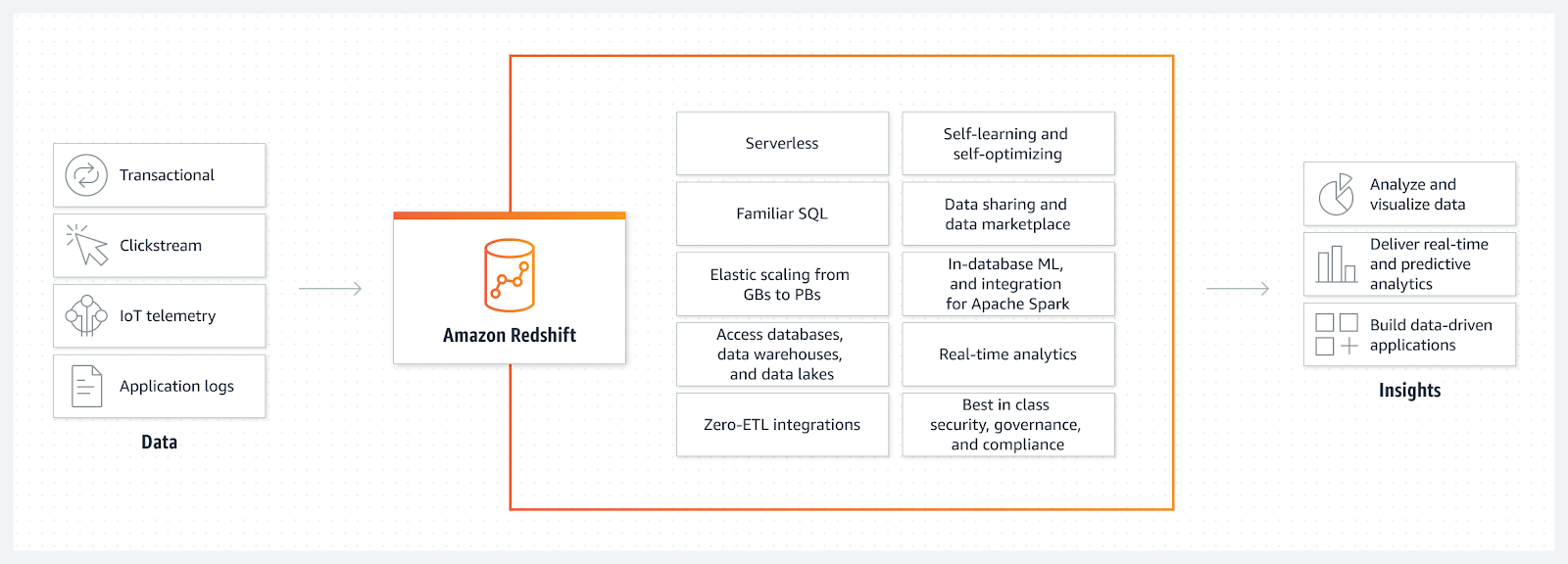
Amazon Redshift Serverless and its capabilities
Amazon Redshift Serverless is Amazon’s fully managed, pay-per-use data warehouse service. It provides customers with an unlimited amount of data warehouse capacity without having to manage any of the underlying infrastructure.
Amazon Redshift Serverless simplifies and streamlines the process of scaling up or down their data warehouses in response to changing demands.
This is why it’s an ideal solution for those looking to manage data warehouse infrastructure without having to worry about scaling.
The service leverages Amazon’s leading cloud technologies and automated setups to provide customers with a seamlessly scalable infrastructure on which they can store and analyze their most important business data.
It offers dynamic scalability so users can create new clusters immediately for peak usage and shut them down when demand is low.
With Amazon Redshift Serverless, customers no longer need to worry about managing complex data warehouse infrastructure and the associated costs – Amazon takes care of all that for them.
The concept of Serverless architecture

With data warehousing infrastructure as its foundation, serverless architecture is an exciting new concept that enables data owners to access data warehouse clusters without having to manage or provision the underlying hardware.
By leveraging the sophisticated Redshift processing units and offering auto-scaling capabilities, Amazon Redshift Serverless allows businesses to focus on data analytics and insights for their applications without worrying about data infrastructure complexities.
As a result, companies can efficiently and cost-effectively manage their data warehouse systems in a flexible environment that is configured to best meet their particular requirements.
How Amazon Redshift Serverless can be used to power data-driven applications

As data scientists look for new ways to scale analytics, Amazon Redshift Serverless provides data teams with powerful data processing capabilities.
Using this Serverless data warehouse, a data engineer can quickly and cost-effectively build data-driven applications.
With automatic scaling enabled and no need for infrastructure provisioning or management, data analysts can focus on complex data queries and derive faster results from their data.
Redshift Serverless also offers advanced analytics capabilities like machine learning algorithms and support for popular query languages like SQL and Spark SQL.
This makes it easier than ever to process large volumes of data quickly while getting insights into customer behavior or other important business metrics in real-time.

This advanced analytics feature set can be used to create predictive models that help businesses make better decisions faster than ever before.
Moreover, with the added ability to seamlessly integrate Amazon Redshift Serverless with other AWS components, organizations can gain access to a wide range of automation and data management services that allow them to unlock the potential of their data in faster, more robust ways.
The benefits of using Amazon Redshift Serverless
Amazon Redshift Serverless is a data warehouse infrastructure solution that provides cost-effective scalability and data processing capabilities.
With its’ pay-per-use model, teams only need to pay for data warehouse resources when in use, making it a practical and budget friendly tool for organizations.

It eliminates tedious data architecture processes and eliminates infrastructure management efforts. Amazon Redshift Serverless is the perfect choice for organizations looking to quickly and easily increase data warehouse capacity without sacrificing performance.
It offers an unprecedented and unique level of scalability through its ability to automatically increase and decrease the number of Redshift Processing Units (RPUs) depending on your workload. RPUs are a measure of compute power, which can be adjusted on-the-fly based on the amount of data you need to process. This allows you to maximize efficiency and minimize costs, while maintaining performance.
Additionally, Amazon Redshift Serverless specializes in optimization of data workloads supporting overbound query executions simultaneously without interrupting data loading processes. This makes the system capable of quickly data processing while keeping costs down. It’s an ideal tool for companies looking to benefit from data storage and analysis capabilities without needing to invest in expensive infrastructure.
Amazon Redshift Serverless is fast and easy to set up in minutes so customers can get started quickly.

The platform supports open file formats such as JSON, Parquet and CSV which makes it easy to load data quickly.
Finally, it offers enhanced security features such as encryption at rest and in transit, which helps keep customer data safe from unauthorized access.
How to get started with Amazon Redshift Serverless
Getting started with Amazon Redshift Serverless couldn’t be easier! With its easy implementation, scalability and automatic serverless scaling features, the data warehouse makes creating a cloud-based analytics environment quick and efficient.

All you need to do is run your first SQL query and Amazon Redshift Serverless takes it from there, managing compute resources in order to best suit your data workloads. By automating the addition of resources when needed, Amazon’s Serverless service is able to reduce costs while providing performance gains and increased scalability. With Amazon Redshift Serverless, you can easily run and scale analytics in minutes.
You also have access to a variety of tools that make it easier to manage and monitor clusters including SQL Workbench/J for query development, Cluster Management Console for monitoring resource utilization, CloudWatch metrics for tracking performance trends over time.
Types of functions that can be run in Amazon Redshift Serverless
Amazon Redshift Serverless supports a variety of functions including data loading, sorting, and joining. Additionally, customers can run aggregations, window functions, user-defined functions (UDFs), and many more operations.
Customers can also use the built-in Amazon Machine Learning to perform predictive analytics on their data.

Furthermore, developers can take advantage of the open source PostgreSQL database engine included with every cluster for custom application development. With all these features at your disposal, you’re sure to find the perfect solution for your data needs!
In addition to running standard SQL queries in Amazon Redshift Serverless , customers can also integrate different business intelligence solutions such as Tableau or PowerBI for visualization and reporting purposes. This makes it easier for businesses to gain insights from their massive datasets.

Overall, Amazon Redshift Serverless provides customers with an efficient and cost-effective solution for managing their data needs. With its scalable architecture and support for various functions, customers are sure to find a solution that meets their requirements.
How can Amazon Redshift Serverless help optimize costs?

Amazon Redshift Serverless is designed to provide cost savings through its automatic scaling capabilities. Since you are only paying for what you use, you can save money by avoiding expensive over-provisioning of resources that would be needed if using a traditional data warehouse.
Additionally, Amazon Redshift Serverless also allows customers to scale down idle clusters thereby minimizing their overall spend on compute and storage costs.
Finally, Amazon Redshift Serverless supports many types of discounts such as Reserved Instances which can further reduce costs.
In conclusion, Amazon Redshift Serverless provides an efficient and cost effective way to handle unpredictable workloads while ensuring optimal performance from your cloud infrastructure.
Migrating data from other systems into Amazon Redshift Serverless
The process of migrating data into Amazon Redshift Serverless can be complex, depending on the type and amount of data being transferred. When considering a move to Amazon Redshift Serverless, it is important to factor in all factors that could impact the migration process such as compatibility with existing systems, security protocols, data transformations, and more.
It is also important to assess your current infrastructure capabilities to ensure that you have the necessary resources available for proper deployment and management of the system.
Conclusion:

In short, Amazon Redshift Serverless is a powerful and cost-effective tool for powering data-driven applications. With its auto-scaling capabilities, users can easily manage data warehouse clusters and take advantage of the flexibility and reliability of Serverless architecture. Through Amazon Redshift Serverless, businesses can save on resources and cost while still deliver optimal performance. Businesses serious about taking advantage of Amazon Redshift Serverless should get started by exploring the different configurations through Amazon Web Services (AWS) Console.
Also read: Binding application code in cloud computing



